| 14.3.1. Regular Expression Syntax | ||
|---|---|---|
 | 14.3. Regular Expressions |  |
| 14.3.1. Regular Expression Syntax | ||
|---|---|---|
| | 14.3. Regular Expressions | |
[ fromfile: regexp.xml id: regexsyntax ]
Following are some of the most commonly used meta-characters.
Special characters
. (the dot matches any character)
\n (matches the newline character)
\f (matches the form feed character)
\t (matches the tab character)
\xhhhh
(matches the Unicode character whose code is the hexadecimal number hhhh in the range 0x0000 to 0xFFFF)
Quantifiers – Modifiers that specify the number of occurrences of the preceding character (or group) that may appear in the matching expression.
+ (1 or more occurrences)
? (0 or 1 occurrences)
* (0 or more occurrences)
{i,j} (at least i but not more than j occurrences)
Character Sets – Sets of allowable values for the character in the specified position of the matching expression. Several character sets are predefined:
\s (matches any whitespace character)
\S (matches any non-whitespace character)
\d (matches any digit character: '0' to '9')
\D (matches any non-digit character)
\w (matches any "word" character; i.e., any letter or digit or the underscore '_')
\W (matches any non-word character)
Character sets can also be specified in square brackets:
[AEIOU] (matches any of the characters 'A', 'E', 'I', 'O', or 'U')
[a-g] (the dash makes this a range from 'a' to 'g')
[^xyz] (matches any character except for 'x', 'y', and 'z')
Grouping and Capturing Characters – (round parentheses) can be used to form a group. Groups can be back-referenced, meaning that if there is a match, the grouped values can be captured and accessed in various ways.
For convenience, up to 9 groups can be referenced within the regular expression by using the identifiers \1 thru \9.
There is also a QRegExp member function cap(int nth), which returns the nth group (as a QString).
Anchoring Characters – Assertions that specify the boundaries of a matching effort.
The caret (^), if it is the first character in the regex, indicates that the match starts at the beginning of the string.
The dollar sign ($), when it is the last character in the regex, means that the effort to match must continue to the end of the string.
In addition, there are word boundary (\b) or non-word boundary (\B) assertions that help to focus the attention of the regex.
Table 14.3. Examples of Regular Expressions
| Pattern | Meaning |
|---|---|
| hello | Matches the literal string, hello
|
| c*at | Quantifier: zero or more occurrences of c, followed by at: at, cat, ccat, etc.
|
| c?at | Matches zero or 1 occurrences of c, followed by at: at or cat only.
|
| c.t | Matches c followed by any character, followed by t: cat, cot, c3t, c%t, etc.
|
| c.*t | Matches c followed by 0 or more characters, followed by t: ct, caaatttt, carsdf$#S8ft, etc.
|
| ca+t | + means 1 or more of the preceding "thing", so this matches cat, caat, caaaat, etc., but not ct.
|
| c\.\*t | Backslashes precede special characters to "escape them" so this matches only the string c.*t
|
| c\\\.t | Matches only the string, c\.t
|
| c[0-9a-c]+z | Between the 'c' and the 'z' one or more of the chars in the set [0-9a-c] – matches strings like c312abbaz and "caa211bac2z"
|
| the (cat|dog) ate the (fish|mouse) | (Alternation) the cat ate the fish or the dog ate the mouse or the dog ate the fish, or the cat ate the mouse |
| \w+ | A sequence of one or more alphanumerics (word chars), same as [a-zA-Z0-9]+
|
| \W | A character which is not part of a word (punctuation, whitespace, etc) |
| \s{5} | Exactly 5 whitespace chars (tabs, spaces, or newlines) |
| ^\s+ | Matches one or more white space at the beginning of the string. |
| \s+$ | Matches one or more white space at the end of the string. |
| ^Help | Matches Help if it occurs at the beginning of the string. |
| [^Help] | Matches any single char except one of the letters in the word Help, anywhere in the string. (a different meaning for the metacharacter ^) |
| \S{1,5} | At least 1, at most 5 non-whitespace (printable characters) |
| \d | A digit [0-9] (and \D is a non-digit, i.e., [^0-9] ) |
| \d{3}-\d{4} | 7-digit phone numbers: 555-1234
|
| \bm[A-Z]\w+ |
\b means word boundary: matches mBuffer but not StreamBuffer
|
![[Note]](png/note-2.png) | Backslashes and C++ Strings |
|---|---|
Backslashes are used for escaping special characters in C++ strings as well, so this means that regular expression strings inside C++ strings must be "double-backslashed" – i.e. every |
| C++ 0x Users |
|---|---|
If your compiler supports C++0x, you may want to use raw quoted strings for regular expressions, to avoid the need to double-escape backslashes. R"(The String Data \ Stuff " )" R"delimiter(The String Data \ Stuff " )delimiter" |
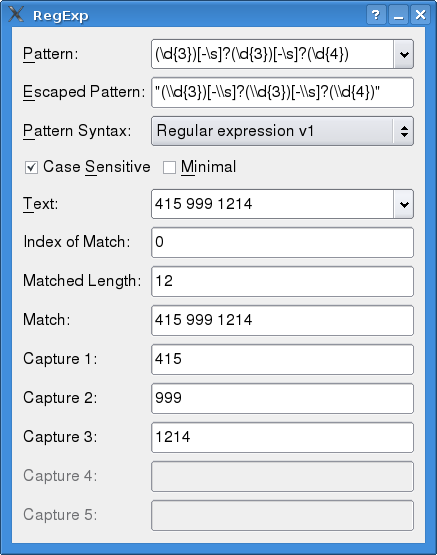
In the meantime, you can explore the capabilities of QRegExp and test your own regular expressions with a Qt example from Nokia.
Figure 14.3 shows a screenshot of the running program.
| Generated: 2012-03-02 | © 2012 Alan Ezust and Paul Ezust. |
| |  | |
| 14.3. Regular Expressions |  | 14.3.2. Regular Expressions: Phone Number Recognition |