| 17.2.2. Parallel Prime Number Calculators | ||
|---|---|---|
 |
17.2. QThread and QtConcurrent |  |
| 17.2.2. Parallel Prime Number Calculators | ||
|---|---|---|
| |
17.2. QThread and QtConcurrent | |
[ fromfile: threads.xml id: primethreads ]
This section presents two different approaches to calculating prime numbers, while sharing work across multiple threads.
The first approach is a producer-consumer model, with a mediator object that is responsible for collecting the results.
Example 17.14 shows a producer class,
PrimeServer.
Example 17.14. src/threads/PrimeThreads/primeserver.h
[ . . . . ] class PrimeServer : public QObject { Q_OBJECT public: explicit PrimeServer(QObject* parent =0); void doCalc(int numThreads, int highestPrime, bool concurrent = false); int nextNumberToCheck(); void foundPrime(int ); bool isRunning() const; public slots: void cancel(); private slots: void handleThreadFinished(); signals: void results(QString); private: int m_numThreads; bool m_isRunning; QList<int> m_primes; int m_nextNumber; int m_highestPrime; QTime m_timer; QMutex m_nextMutex; QMutex m_listMutex; QSet<QObject*> m_threads; private slots: void handleWatcherFinished(); void doConcurrent(); private: bool m_concurrent; int m_generateTime;QFutureWatcher<void> m_watcher; }; [ . . . . ]
|
|
Time spent generating input data. |
The PrimeServer creates PrimeThreads (consumers)
to do the actual work.
Child PrimeThreads are created and started in Example 17.15.
Example 17.15. src/threads/PrimeThreads/primeserver.cpp
[ . . . . ]
void PrimeServer::
doCalc(int numThreads, int highestPrime, bool concurrent) {
m_isRunning = true;
m_numThreads = numThreads;
m_concurrent = concurrent;
m_highestPrime = highestPrime;
m_primes.clear();
m_primes << 2 << 3;
m_threads.clear();
m_nextNumber = 3;
m_timer.start();
if (!concurrent) {
for (int i=0; i<m_numThreads; ++i) {
PrimeThread *pt = new PrimeThread(this);
connect (pt, SIGNAL(finished()), this,
SLOT(handleThreadFinished()));
m_threads << pt;
pt->start();  }
}
else doConcurrent();
}
}
}
else doConcurrent();
}
|
|
Child thread is not started yet. |
|
|
Child thread executes run(). |
PrimeThread, shown in Example 17.16, is a custom QThread that overrides run().
Example 17.16. src/threads/PrimeThreads/primethread.h
The run() method, shown in Example 17.17, is doing a single
prime number test between two method calls to the QMutexLocker methods of
PrimeServer, in a tight loop.
Example 17.17. src/threads/PrimeThreads/primethread.cpp
[ . . . . ]
PrimeThread::PrimeThread(PrimeServer *parent)
: QThread(parent), m_server(parent) { }
void PrimeThread::run() {
int numToCheck = m_server->nextNumberToCheck();
while (numToCheck != -1) {
if (isPrime(numToCheck))
m_server->foundPrime(numToCheck);
numToCheck = m_server->nextNumberToCheck();
}
}
[ . . . . ]
PrimeServer locks a QMutex via a QMutexLocker, which safely locks and unlocks its QMutex as the program enters and leaves the enclosing block scope, as shown in Example 17.18. Originally, this program used a single mutex to protect both methods, but because the data accessed are independent from each other, you can increase parallelism possibilities by using independent mutexes for each method.
Example 17.18. src/threads/PrimeThreads/primeserver.cpp
[ . . . . ]
int PrimeServer::nextNumberToCheck() {
QMutexLocker locker(&m_nextMutex);
if (m_nextNumber >= m_highestPrime) {
return -1;
}
else {
m_nextNumber+= 2;
return m_nextNumber;
}
}
void PrimeServer::foundPrime(int pn) {
QMutexLocker locker(&m_listMutex);
m_primes << pn;
}
|
|
Scope-based mutex works from multiple return points. |
|
|
This method also must be made thread-safe. |
These methods are thread-safe because simultaneous calls from multiple threads block one another. This is one way of serializing access to critical shared data.
Example 17.19. src/threads/PrimeThreads/primeserver.cpp
[ . . . . ]
void PrimeServer::cancel() {
QMutexLocker locker(&m_nextMutex);
m_nextNumber = m_highestPrime+1;
The cancel method, shown in Example 17.19 is meant to be called
in a nonblocking way, so that a GUI can continue responding to events while the PrimeThread safely exits its loop and returns from run().
In Example 17.20, the server cleans up
each finished thread and reports the results when all of them have finished.
It uses QObject::sender()
to obtain the signal sender, and deletes it safely with deleteLater().
This is a recommended and safe way to terminate and clean up threads.
Example 17.20. src/threads/PrimeThreads/primeserver.cpp
[ . . . . ]
void PrimeServer::handleThreadFinished() {
QObject* pt = sender();
m_threads.remove(pt);
pt->deleteLater();
if (!m_threads.isEmpty()) return;
int numPrimes = m_primes.length();
QString result = QString("%1 mutex'd threads %2 primes in %3"
"miliseconds. ").arg(m_numThreads)
.arg(numPrimes).arg( m_timer.elapsed());
QString r2 = QString(" %1 kp/s")
.arg(numPrimes / m_timer.elapsed());
qDebug() << result << r2;
emit results(result + r2);
m_isRunning = false;
}
|
|
The QThread is our sender. |
|
|
Others are still running. |
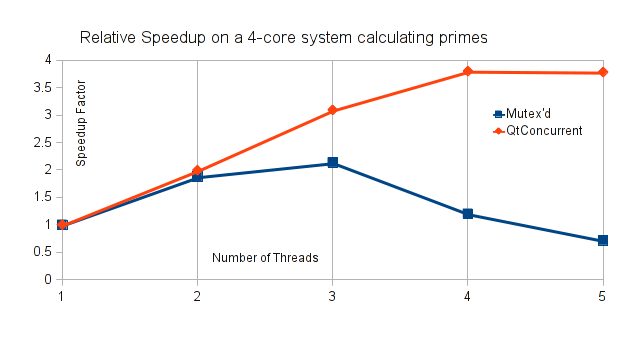
Some results from testing 100,000,000 numbers are summarized in Figure 17.6. The line marked "Mutex'd" shows the speedup factor observed from running the producer-consumer algorithm above with n worker threads. As you can see, the best speedup factor we have is at 3, and the performance goes down after that. This could be due to the fact that there is also a producer thread that could be quite busy, and not counted in the graph.
The other line marked "QtConcurrent" shows
almost optimal speedup factors (1:1) as we reach 4 threads on a 4-core system,
and no noticable degradation as we increase the number of threads beyond that.
This is from using the same isPrime() function concurrently, in Example 17.22.
This graph is focused on relative speedup factors compared to the same algorithm running with a single thread, but what it does show is the absolute speeds. If you try running the example, you will find that the QtConcurrent approach runs at least 10 times faster overall, in all tests.
The efficiency of a parallel algorithm depends on keeping all cores busy doing calculations, rather than waiting for each other to synchronize. The more relative time is spent in synchronization points, the worse an algorithm performs as you add more threads.
Instead of creating and managing your own threads, you can use the QtConcurrent filter()
algorithm, to filter non-primes from a list of numbers.
QtConcurrent algorithms
automatically distribute the work across an arbitrary number of threads, as specified by the global QThreadPool.
The algorithms accept a container, and function pointer, or a functor, which gets performed on each item in the
container.
Example 17.21 shows the data members used by the concurrent algorithm in PrimeServer. You can use a QFutureWatcher to perform non-busy waiting for the end of the calculation.
Example 17.21. src/threads/PrimeThreads/primeserver.h
[ . . . . ]
private slots:
void handleWatcherFinished();
void doConcurrent();
private:
bool m_concurrent;
int m_generateTime;
QFutureWatcher<void> m_watcher;
};
|
|
Time spent generating input data. |
Example 17.22 shows a functional
programming styled approach to the solution.
The nonblocking filter() function returns immediately with a value of type
QFuture.
You can send that to a QFutureWatcher to
monitor progress of the calculation.
Example 17.22. src/threads/PrimeThreads/primeserver.cpp
[ . . . . ]
void PrimeServer::doConcurrent() {
QThreadPool::globalInstance()->setMaxThreadCount(m_numThreads);
m_primes.clear();
m_primes << 2;
for (m_nextNumber=3; m_nextNumber<=m_highestPrime;
m_nextNumber += 2) {
m_primes << m_nextNumber;
}
m_generateTime = m_timer.elapsed();
qDebug() << m_generateTime << "Generated "
<< m_primes.length() << " numbers";
connect (&m_watcher, SIGNAL(finished()), this,
SLOT(handleWatcherFinished()));
m_watcher.setFuture(
QtConcurrent::filter(m_primes, isPrime));
}
void PrimeServer::handleWatcherFinished() {
int numPrimes = m_primes.length();
int msecs = m_timer.elapsed();
QString result =
QString("%1 thread pool %2 primes in %4/%3 milliseconds"
"(%5% in QtConcurrent).") .arg(m_numThreads)
.arg(numPrimes).arg(msecs).arg(msecs-m_generateTime)
.arg((100.0 * (msecs-m_generateTime)) / msecs);
QString r2 = QString(" %1 kp/s").arg(numPrimes / msecs);
qDebug() << result << r2;
m_watcher.disconnect(this);
emit results(result + r2);
m_isRunning = false;
}
|
|
QFutureWatcher for monitoring progress. |
|
|
Non-blocking, in-place filter() returns a QFuture. |
| Generated: 2012-03-02 | © 2012 Alan Ezust and Paul Ezust. |
| |
 |
|
17.2.1. Thread Safety and QObjects |
 |
17.2.3. Concurrent Map/Reduce Example |